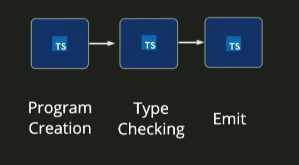
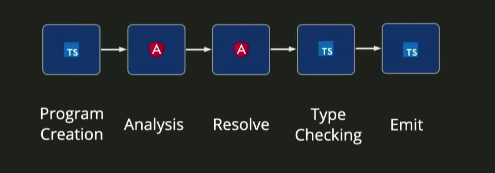
要了解它是如何工作的,我们首先需要意识到在设计上,Javascript 的整个运行时是可以被重写覆盖的。如果我们希望,我们可以重写在 String 或 Number 中的方法(String.prototype.trim = function(){}之类的)。
覆盖浏览器默认行为
发生的情况是,Angular 在启动时会给一些低级浏览器 API 打补丁,比如 addEventListener,这是用于注册所有浏览器事件(包括 click handlers)的浏览器函数。Angular 会把 addEventListener 替换为一个等效的新版本:
1 2 3 4 5 6 7 8 9 10 11 12 13
// this is the new version of addEventListener functionaddEventListener(eventName, callback) { // call the real addEventListener callRealAddEventListener(eventName, function() { // first call the original callback callback(...); // and then run Angular-specific functionality var changed = angular2.runChangeDetection(); if (changed) { angular2.reRenderUIPart(); } }); }
❯ ng serve Your global Angular CLI version (8.3.17) is greater than your local version (6.2.9). The local Angular CLI version is used.
To disable this warning use "ng config -g cli.warnings.versionMismatch false". Cannot destructure property `createHash` of 'undefined' or 'null'. TypeError: Cannot destructure property `createHash` of 'undefined' or 'null'.
Function instances that can be used as a constructor have a prototype property. Whenever such a function instance is created another ordinary object is also created and is the initial value of the function’s prototype property. Unless otherwise specified, the value of the prototype property is used to initialize the [[Prototype]] internal slot of the object created when that function is invoked as a constructor.
NOTE
Function objects created using Function.prototype.bind, or by evaluating a MethodDefinition (that are not a GeneratorMethod) or an ArrowFunction grammar production do not have a prototype property.
“Side Effect” is not a react-specific term. It is a general concept about behaviours of functions. A function is said to have side effect if it trys to modify anything outside its body. For example, if it modidifies a global variable, then it is a side effect. If it makes a network call, it is a side effect as well. source
A “side effect” is anything that affects something outside the scope of the function being executed. These can be, say, a network request, which has your code communicating with a third party (and thus making the request, causing logs to be recorded, caches to be saved or updated, all sorts of effects that are outside the function.
There are more subtle side effects, too. Changing the value of a closure-scoped variable is a side effect. Pushing a new item onto an array that was passed in as an argument is a side effect. Functions that execute without side effects are called “pure” functions: they take in arguments, and they return values. Nothing else happens upon executing the function. This makes the easy to test, simple to reason about, and functions that meet this description have all sorts of useful properties when it comes to optimization or refactoring.
Pure functions are deterministic (meaning that, given an input, they always return the same output), but that doesn’t mean that all impure functions have side effects. Generating a random value within a function makes it impure, but isn’t a side effect, for example. React is all about pure functions, and asks that you keep several lifecycle methods pure, so these are good questions to be asking.
* What went wrong: Execution failed for task ':app:lintVitalRelease'. > Could not resolve all files for configuration ':app:lintClassPath'. > Could not resolve org.jvnet.staxex:stax-ex:1.7.7. Required by: project :app > com.android.tools.lint:lint-gradle:26.2.1 > com.android.tools:sdk-common:26.2.1 > com.android.tools:sdklib:26.2.1 > com.android.tools:repository:26.2.1 > org.glassfish.jaxb:jaxb-runtime:2.2.11 > Could not resolve org.jvnet.staxex:stax-ex:1.7.7. > Could not get resource 'https://jitpack.io/org/jvnet/staxex/stax-ex/1.7.7/stax-ex-1.7.7.jar'. > Could not HEAD 'https://jitpack.io/org/jvnet/staxex/stax-ex/1.7.7/stax-ex-1.7.7.jar'. Received status code 522 from server: Origin Connection Time-out > Could not resolve com.sun.xml.fastinfoset:FastInfoset:1.2.13. Required by: project :app > com.android.tools.lint:lint-gradle:26.2.1 > com.android.tools:sdk-common:26.2.1 > com.android.tools:sdklib:26.2.1 > com.android.tools:repository:26.2.1 > org.glassfish.jaxb:jaxb-runtime:2.2.11 > Could not resolve com.sun.xml.fastinfoset:FastInfoset:1.2.13. > Could not get resource 'https://jitpack.io/com/sun/xml/fastinfoset/FastInfoset/1.2.13/FastInfoset-1.2.13.jar'. > Could not HEAD 'https://jitpack.io/com/sun/xml/fastinfoset/FastInfoset/1.2.13/FastInfoset-1.2.13.jar'. Received status code 522 from server: Origin Connection Time-out
// Turn all of that into a JSON string echo $fractal->createData($resource)->toJson();
// 输出: {"data":[{"id":1,"title":"Hogfather","year":1998,"author":{"name":"Philip K Dick","email":"philip@example.org"}},{"id":2,"title":"Game Of Kill Everyone","year":2014,"author":{"name":"George R. R. Satan","email":"george@example.org"}}]}
Some of the following names are regional or contextual.
( ) – parentheses, brackets (UK, Canada, New Zealand, South Africa and Australia), parens, round brackets, soft brackets, first brackets or circle brackets
[ ] – square brackets, closed brackets, hard brackets, second brackets, crotchets,[3] or brackets (US)
{ } – braces are “two connecting marks used in printing”; and in music “to connect staves to be performed at the same time”[4] (UK and US), French brackets, curly brackets, definite brackets, swirly brackets, curly braces, birdie brackets, Scottish brackets, squirrelly brackets, gullwings, seagulls, squiggly brackets, twirly brackets, Tuborg brackets (DK), accolades (NL), pointy brackets, third brackets, fancy brackets.
< > – inequality signs, pointy brackets, or brackets. Sometimes referred to as angle brackets, in such cases as HTML markup. Occasionally known as broken brackets or brokets.[5]
⸤ ⸥; 「 」 – corner brackets
⟦ ⟧ – double square brackets, white square brackets
Guillemets, ‹ › and « », are sometimes referred to as chevrons or [double] angle brackets.[1]
The for…in loop will iterate over all enumerable properties of an object.
for in 循环会遍历一个对象上面的所有enumerable属性。
The for…of syntax is specific to collections, rather than all objects. It will iterate in this manner over the elements of any collection that has a [Symbol.iterator] property.
for of 语法是针对集合的,而不是所有的对象。它会遍历定义了[Symbol.iterator]属性的集合的所有元素。
The following example shows the difference between a for…of loop and a for…in loop.
MDN的例子如下:
1 2 3 4 5 6 7 8 9 10
Object.prototype.objCustom = function() {}; Array.prototype.arrCustom = function() {}; let iterable = [3, 5, 7]; iterable.foo = 'hello'; for (let i in iterable) { console.log(i); // logs 0, 1, 2, "foo", "arrCustom", "objCustom" } for (let i of iterable) { console.log(i); // logs 3, 5, 7 }
process.on('uncaughtException', (err) => { console.error('whoops! there was an error'); });
myEmitter.emit('error', newError('whoops!')); // Prints: whoops! there was an error
坠吼还是总给’error’事件注册上监听器
1 2 3 4 5 6
const myEmitter = new MyEmitter(); myEmitter.on('error', (err) => { console.error('whoops! there was an error'); }); myEmitter.emit('error', newError('whoops!')); // Prints: whoops! there was an error
const myEmitter = new MyEmitter(); // Only do this once so we don't loop forever myEmitter.once('newListener', (event, listener) => { if (event === 'event') { // Insert a new listener in front myEmitter.on('event', () => { console.log('B'); }); } }); myEmitter.on('event', () => { console.log('A'); }); myEmitter.emit('event'); // Prints: // B // A
// callbackA removes listener callbackB but it will still be called. // Internal listener array at time of emit [callbackA, callbackB] myEmitter.emit('event'); // Prints: // A // B
// callbackB is now removed. // Internal listener array [callbackA] myEmitter.emit('event'); // Prints: // A
const server = http.createServer( (req, res) => { // req is an http.IncomingMessage, which is a Readable Stream // res is an http.ServerResponse, which is a Writable Stream
let body = ''; // Get the data as utf8 strings. // If an encoding is not set, Buffer objects will be received. req.setEncoding('utf8');
// Readable streams emit 'data' events once a listener is added req.on('data', (chunk) => { body += chunk; });
// the end event indicates that the entire body has been received req.on('end', () => { try { const data = JSON.parse(body); // write back something interesting to the user: res.write(typeof data); res.end(); } catch (er) { // uh oh! bad json! res.statusCode = 400; return res.end(`error: ${er.message}`); } }); });